TensorFlow-VGG16模型复现
VGG介绍
VGG全称是指牛津大学的Oxford Visual Geometry Group,该小组在2014年的ImageNet挑战赛中,设计的VGG神经网络模型在定位和分类跟踪比赛中分别取得了第一名和第二名的成绩。
论文指出其主要贡献在于:利用3*3小卷积核的网络结构对逐渐加深的网络进行全面的评估,结果表明加深网络深度到16至19层可极大超越前人的网络结构。
VGG结构特点
- 训练输入:固定尺寸
224*224的RGB图像 - 预处理:每个像素值减去训练集上的RGB均值
- 卷积核:一系列
3*3卷积核堆叠,步长为1,采用padding保持卷积后图像空间分辨率不变 - 空间池化:紧随卷积“堆”的最大池化,为
2*2滑动窗口,步长为2 - 全连接层:特征提取完成后,接三个全连接层,前两个为
4096通道,第三个为1000通道,最后是一个soft-max层,输出概率 - 所有隐藏层都用非线性修正
ReLu
详细配置
表中每列代表不同的网络,只有深度不同(层数计算不包含池化层)。卷积的通道数量很小,第一层仅64通道,每经过一次最大池化,通道数翻倍,直到数量达到512通道。
对比每种模型的参数数量,尽管网络加深,但权重并未大幅增加,因为参数量主要集中在全连接层。
最后两列(D列和E列)是效果较好的VGG-16和VGG-19的模型结构,本文将用TensorFlow代码复现VGG-16模型,并使用训练好的模型参数文件进行图片物体分类测试。
| 11 weight layers |
11 weight layers |
13 weight layers |
16 weight layers |
16 weight layers |
19 weight layers |
| conv3-64 | conv3-64 LRN |
conv3-64 conv3-64 |
conv3-64 conv3-64 |
conv3-64 conv3-64 |
conv3-64 conv3-64 |
| conv3-128 | conv3-128 | conv3-128 conv3-128 |
conv3-128 conv3-128 |
conv3-128 conv3-128 |
conv3-128 conv3-128 |
| conv3-256 conv3-256 |
conv3-256 conv3-256 |
conv3-256 conv3-256 |
conv3-256 conv3-256 conv1-256 |
conv3-256 conv3-256 conv3-256 |
conv3-256 conv3-256 conv3-256 conv3-256 |
| conv3-512 conv3-512 |
conv3-512 conv3-512 |
conv3-512 conv3-512 |
conv3-512 conv3-512 conv1-512 |
conv3-512 conv3-512 conv3-512 |
conv3-512 conv3-512 conv3-512 conv3-512 |
| conv3-512 conv3-512 |
conv3-512 conv3-512 |
conv3-512 conv3-512 |
conv3-512 conv3-512 conv1-512 |
conv3-512 conv3-512 conv3-512 |
conv3-512 conv3-512 conv3-512 conv3-512 |
论文中介绍的训练方法
- 训练方法基本与AlexNet一致,除了多尺度训练图像采样方法不一致
- 训练采用mini-batch梯度下降法,batch size=256
- 采用动量优化算法,momentum=0.9
- 采用L2正则化方法,惩罚系数0.00005,dropout比率设为0.5
- 初始学习率为0.001,当验证集准确率不再提高时,学习率衰减为原来的0.1倍,总共下降三次
- 总迭代次数为370K(74epochs)
- 数据增强采用随机裁剪,水平翻转,RGB颜色变化
- 设置训练图片大小的两种方法(定义S代表经过各向同性缩放的训练图像的最小边):
- 第一种方法针对单尺寸图像训练,S=256或384,输入图片从中随机裁剪224*224大小的图片,原则上S可以取任意不小于224的值
- 第二种方法是多尺度训练,每张图像单独从[Smin ,Smax ]中随机选取S来进行尺寸缩放,由于图像中目标物体尺寸不定,因此训练中采用这种方法是有效的,可看作一种尺寸抖动的训练集数据增强
论文中提到,网络权重的初始化非常重要,由于深度网络梯度的不稳定性,不合适的初始化会阻碍网络的学习。因此先训练浅层网络,再用训练好的浅层网络去初始化深层网络.
VGG-16网络复现
VGG-16网络结构(前向传播)复现
复现VGG-16的16层网络结构,将其封装在一个Vgg16类中,注意这里我们使用已训练好的vgg16.npy参数文件,不需要自己再对模型训练,因而不需要编写用于训练的反向传播函数,只编写用于测试的前向传播部分即可。
下面代码我已添加详细注释,并添加一些print语句用于输出网络在每一层时的结构尺寸信息。
vgg16.py
1 | import inspect |
图片加载显示与预处理
测试图片需要进行必要的预处理操作(尺寸裁剪,像素归一化等),并使用matplotlib将原始图片以及预处理用于测试的图片显示出来。
utils.py
1 | from skimage import io, transform |
物体种类列表
此文件保存1000中预测结果编号对应的真实物体的名称,用于将最后的预测id对应为物体名称。
Nclasses.py
1 | # 每个图像的真实标签,以及对应的索引值 |
物体分类测试接口函数
编写接口函数,用于测试图片的加载,模型运行的调用,预测结果的显示等。
app.py
1 | import numpy as np |
VGG-16图片分类测试
测试结果
1 | Python 3.6.8 (tags/v3.6.8:3c6b436a57, Dec 24 2018, 00:16:47) [MSC v.1916 64 bit (AMD64)] on win32 |

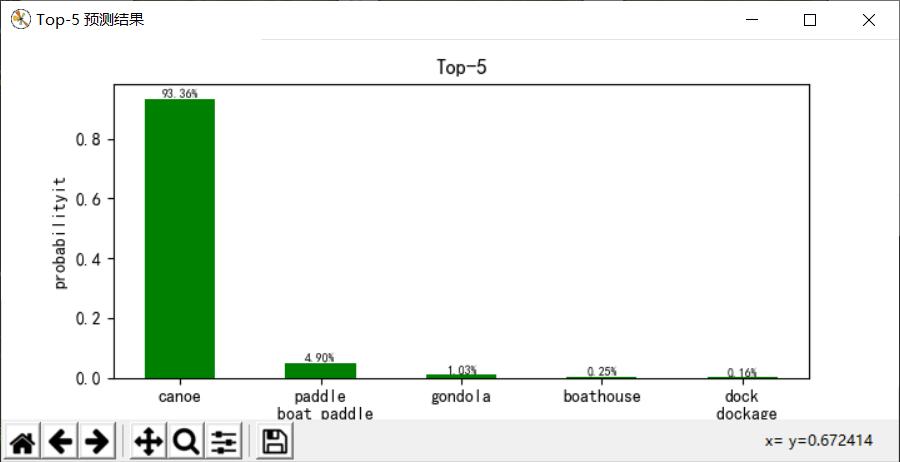
结果分析
选用这张小船的图片(/pic/8.jpg)进行测试,程序先加载训练模型参数文件(vgg16.npy),里面以字典形式保存网路参数(权重偏置等),可以打印显示键值名称,之后进行网络的前向传播,图片输入为:224x224x3,随着网络层数加深,数据尺寸不断减小,厚度不断增加,变为7x7x512后,被拉伸为1列数据,之后经过3层全连接层以及softmax分类输出,最终模型给出Top5预测结果,以93.36%的把握认为图片是canoe(独木舟,轻舟),4.90%的把握认为是paddle boat paddle(桨划船),预测效果还是不错的。






