python读取excel进行数据处理并保存为新的excel结果
一般需要数据处理时我们会使用excel表格,并可使用其自带的求和、排序等功能对数据进行处理,但对于某些复杂的处理,我们可以使用python工具来读取excel数据,并通过python编程,来实现自己所需要的数据处理结果和数据保存方式。
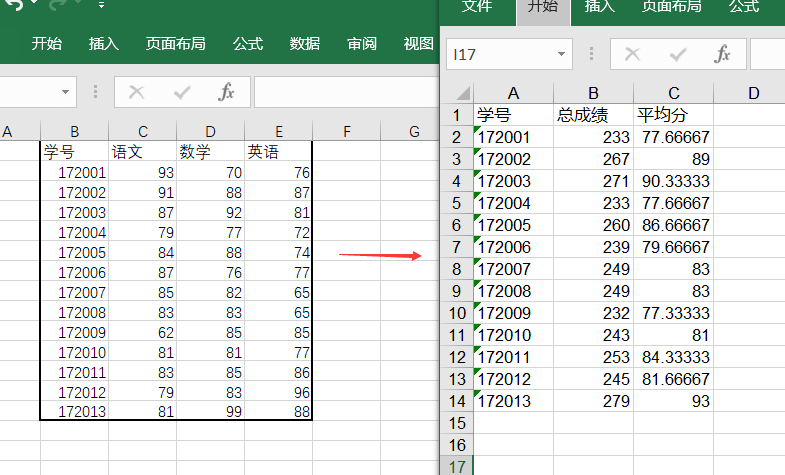
下面以一组学生成绩数据为例,计算每行的总分和平均分,并将最终结果连同学号保存到新的excel中,最终效果如下,左边是原始数据excel文件,右边为数据处理后生成的excel结果文件:
代码
代码如下,已经加了详细注释,需要注意的是,程序中data = ori.iloc[0:,1:5]这句中:
0:指定行的范围:表示行数据从0到最后一行,这样就不需要具体指定最后一行是多少行,另外,这里的0实际是excel中的第2行,可能是因为默认把excel的第1行当作是数据的表头,就跳过了吧1:5指定列的范围:这里其实是左闭右开,即1到4,即excel中的第2列到5列(注意0才是第1列)
为了确定读取的是否正确,可以先打印出部分读取的数据确认一下,如先读取5行。
1 | import numpy as np |
运行
准备自己需要的excel原始文件,我的是data1.xlsx,其它文件名可自行修改python程序中的文件名即可。
运行效果如下:
1 | Python 3.6.8 (tags/v3.6.8:3c6b436a57, Dec 24 2018, 00:16:47) [MSC v.1916 64 bit (AMD64)] on win32 |
运行后自动生成一个以”原文件名-result”的excel结果文件,如下图:

-------------纸短情长 下次再见-------------
关注微信公众号,获取更多精彩~
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 码农爱学习的博客!
评论
公告
分享:单片机、嵌入式、ARM、Linux、C/C++、python等技术文章~ 




